EventBridge Pipes で Tweet をあれこれする - あなたと「|」したい...後記 -
この記事は AWS LambdaとServerless Advent Calendar 2022 の25日目の記事です。
12/20 にこんな LT をしました。
5 分の中で説明とデモまでやったので、爆速 LT となり話しきれなかったことも多く、この記事では LT 用に作ったデモアプリケーションの補足をしていきます。
目次
- 目次
- 事前知識としてメインで利用するサービスについて
- デモアプリケーションの概要
- 1. Pipes のフィルター処理
- 2. Pipes の Enrich 処理用の Step Functions
- 3. バッチサイズを指定した時の挙動
- 4. その他細かいけど伝えたいこと
- 困ったポイント
- さいごに
事前知識としてメインで利用するサービスについて
Amazon EventBridge とは
LT では、AWS re:invent 2022 で発表された Amazon EventBridge Pipes という新機能を軸にしたデモアプリケーションを作りました。
そもそも Amazon EventBridge とはどんなサービスなのかというと、その名の通りイベント(Event)をプロデューサーとコンシューマー間で橋渡し(Bridge)してくれるサービスです。
イベントとは「状態が変更されたことを示すシグナル」であると AWS ではよく言いますが、EventBridge では「S3 にオブジェクトをアップロードした」「EC2 を起動した」といったイベントをトリガーにして何か他のイベントドリブンな AWS サービスや外部 API を呼び出す、Push 型での情報連携(イベント通知)を可能にするイベントバスが提供されていました。
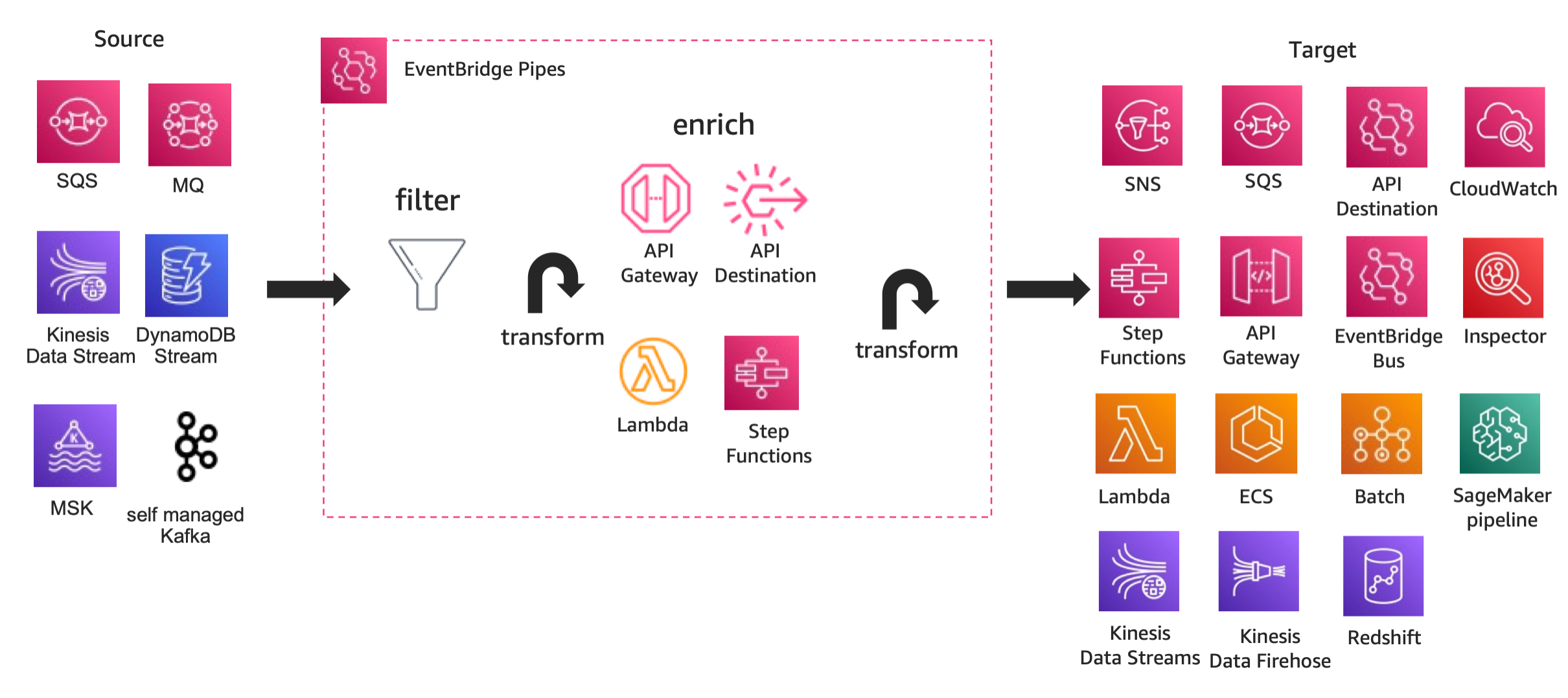
re:invent 2022 で発表された EventBridge Pipes とは
EventBridge Pipes も基本的にはこのイベントを橋渡しするという思想に則っているのですが、イベントソースとなるサービスが SQS・Kinesis Data Streams・DynamoDB Streams・Kafka という、いわゆるアプリケーションとしてのメッセージングやイベントデータを取り扱うというのが一つ大きく異なる点です。
これらのイベントソースではデータを取得する際、コンシューマーが AWS Lambda である時を除き、自分達でポーリングや、DeleteMessage(SQSの場合) を行う必要がありました。
この Lambda サービスのみがやってくれていた Event Source Mapping の部分を EventBridge Pipes で実現可能になり、Lambda に限らないさまざまなイベントコンシューマーにつなぐことができるようになりました。
また、EventBridge Pipes が発表された際、UNIX pipe(「|」)が引き合いに出ていました。まさに同じようにシームレスにデータをフィルター・加工するための機能が提供されるのも特徴です。
こちらの記事にある図の Lambda Function の前段で Lambda サービスが行なってきた処理部分を EventBridge Pipes が担ってくれるイメージです。

EventBridge Pipes の構成要素は以下の通りです。
- イベントソース: SQS・Kinesis Data Streams・DynamoDB Streams・Kafka(MSK もセルフマネージドなものも)をイベントソース(プロデューサー)として利用できます。
- フィルター: イベントデータのフィルタリングがオプションで利用できます。EventBridge に組み込まれているパターンフィルターのルールを使います。EventBridge Pipes の料金としてフィルターされて通されたデータのみが課金対象なのは嬉しいところです。
- Enrich: 加工フェーズでは API Gateway・API Destinations による外部 API 呼び出し・Lambda関数・StepFunctions(Express ワークフローのみ)を利用できます。またその前段で組み込みの input transformation で入力 Payload の簡易な変換・整形が可能です。
- ターゲット: 図に書かれているようなさまざま選択肢をターゲット(コンシューマー)として利用できます。また Enrich フェーズ同様、コンシューマーの前段で 組み込みの input transformation 処理を利用可能です。
デモアプリケーションの概要
「なぜこのデモアプリ作ったの?」的なモチベーションのところはスライドを見てください、超くだらないです。
tail -f /var/log/tweet.log | grep 'はまーん' | sed -e 's/$/でもそこが好き...♡/' をEventBridge Pipes で実現していきます。sed のところはせっかくなので AWS の AI サービスを絡めて条件分岐もつけていきます。
アプリケーションとしてやっていることは、以下の通りシンプルです。
- Twitter で特定のハッシュタグのツイートをストリーミング(イベントプロデューサー)
- はまーんというフレーズでフィルタリング
- ネガティブなツイートだったらツイート本文を加工(語尾に「でもそこが好き」とつける)
- Log データとして書き込む(イベントコンシューマー)
出来上がったアーキテクチャがこちらです。
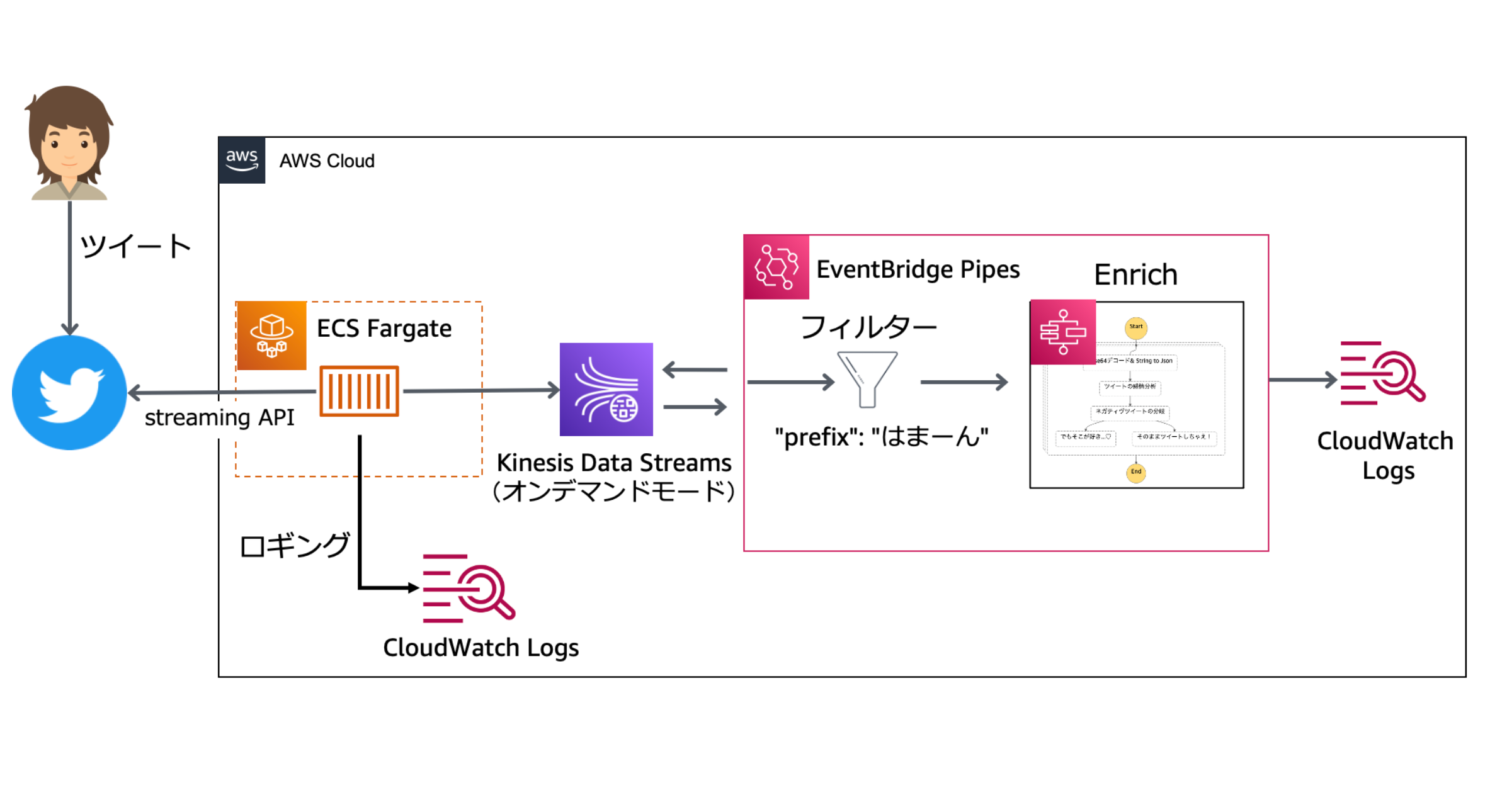
構成要素としては以下のような AWS サービスを利用しました。
- Twitter からのデータ取得: ECS Fargate
- イベントプロデューサー: Kinesis Data Streams
- イベントデータのあれこれ: EventBridge Pipes
- フィルター: Pipes のフィルタリング機能
- Enrich: Step Functions の Express ワークフロー
- イベントコンシューマー: CloudWatch Logs
意識したポイントとしては、「できる限りコードを書いて解決しようとしない」 ことです。
結果的に最初のTwitter のデータ取得処理(ECS Fargate で実行している部分)以外は基本プログラミング言語による実装はしていません。Enrich のところも Step Functions で組み込み関数や SDK 統合のみで実現しており、ノーコードとは言いませんが、ローコードに近い形でデモアプリケーションを構築できました。
実際に構築した上での特筆すべきポイントについて、いくつか書いていきます。
1. Pipes のフィルター処理
まずは基本的なところですが、イベントソースから取得した各レコードは、オプショナルで組み込みのフィルター機能を通ります(未設定ならスキップ)。
利用できる比較演算子は以下のようなものが使えます(ドキュメント)。Lambda のイベントソースマッピングと同じものが使えます。
| 比較演算子 | 例 | シンタックス |
|---|---|---|
| Null | UserID が null である | “UserID”: [ null ] |
| Empty | LastName が 空文字列 である | “LastName”: [""] |
| Equals | Name が “Alice"である | “Name”: [ “Alice” ] |
| And | Locationが “New York” かつ Day が “Monday"である | “Location”: [ “New York” ], “Day”: [“Monday”] |
| Or | PaymentType が “Credit” もしくは “Debit"である | “PaymentType”: [ “Credit”, “Debit”] |
| Not | Weather が “Raining” では無い | “Weather”: [ { “anything-but”: [ “Raining” ] } ] |
| Numeric (equals) | Price が 100 である | “Price”: [ { “numeric”: [ “=”, 100 ] } ] |
| Numeric (range) | Price が 10より多く ~ 20未満である | “Price”: [ { “numeric”: [ “>”, 10, “<=”, 20 ] } ] |
| Exists | プロパティProductName が存在している | “ProductName”: [ { “exists”: true } ] |
| Does not exist | プロパティProductName が存在していない | “ProductName”: [ { “exists”: false } ] |
| Begins with | Region が us-から始まる | “Region”: [ {“prefix”: “us-” } ] |
本当は grep 的なことしたかったのですが、見渡す限り like 検索のようなことはできませんでした。仕方がないので、Prefix でフィルタリングを書きました。
{
"data": {
"body": [{
"prefix": "はまーん"
}]
}
}
デモアプリケーションでは、イベントソースとして Kinesis Data Streams を使っており、以下のようなレコードが流れてきます(後述しますが、バッチ取得の設定をすると配列で流れてきます))
{
"eventSource": "aws:kinesis",
"eventVersion": "1.0",
"eventID": "shardId-000000000003:49636128099310532220030796778683432438386605224756248626",
"eventName": "aws:kinesis:record",
"invokeIdentityArn": "arn:aws:iam::xxxxxxxxxxxx:role/service-role/Amazon_EventBridge_Pipe_twitter-hama-pipe_xxxxxxxx",
"awsRegion": "us-east-1",
"eventSourceARN": "arn:aws:kinesis:us-east-1:xxxxxxxxxxxx:stream/events-pipe-app-streams",
"kinesisSchemaVersion": "1.0",
"partitionKey": "1603563410146222080",
"sequenceNumber": "49636128099310532220030796778683432438386605224756248626",
"data": "eyJuYW1lIjoi44Go44KJIiwidHdpdHRlcl9pZCI6InRvcmF0b3JhM2oiLCJjcmVhdGVkX2F0IjoiMjAyMi0xMi0xNlQwMTozMToyNC4wMDBaIiwiYm9keSI6IuOBr+OBvuODvOOCk+acgOS9ju+8ge+8ge+8gVxuICNuYWthbm9zaGltYV9kZXYifQ==",
"approximateArrivalTimestamp": 1671154290.212
}
Kinesis に書き出したデータは base64 でエンコードされていますが、デコードするとこんな実データを入れています。
{"name":"とら","twitter_id":"toratora3j","created_at":"2022-12-16T01:31:24.000Z","body":"はまーん最低!!!\n #nakanoshima_dev"}
というわけで data からさらに本文(body)階層まで潜ってフィルターしています。
この時のフィルター時の Base64 デコードが気になりますが、Pipes が裏側でやってくれるので、意識せずに使えます。
その他フィルターフェーズについてのドキュメントはこちらをご覧ください
2. Pipes の Enrich 処理用の Step Functions
レコードの加工フェーズです。今回 Step Functions(Express ワークフロー) を使っています。
Step Functions ではこんなフローを作りました。
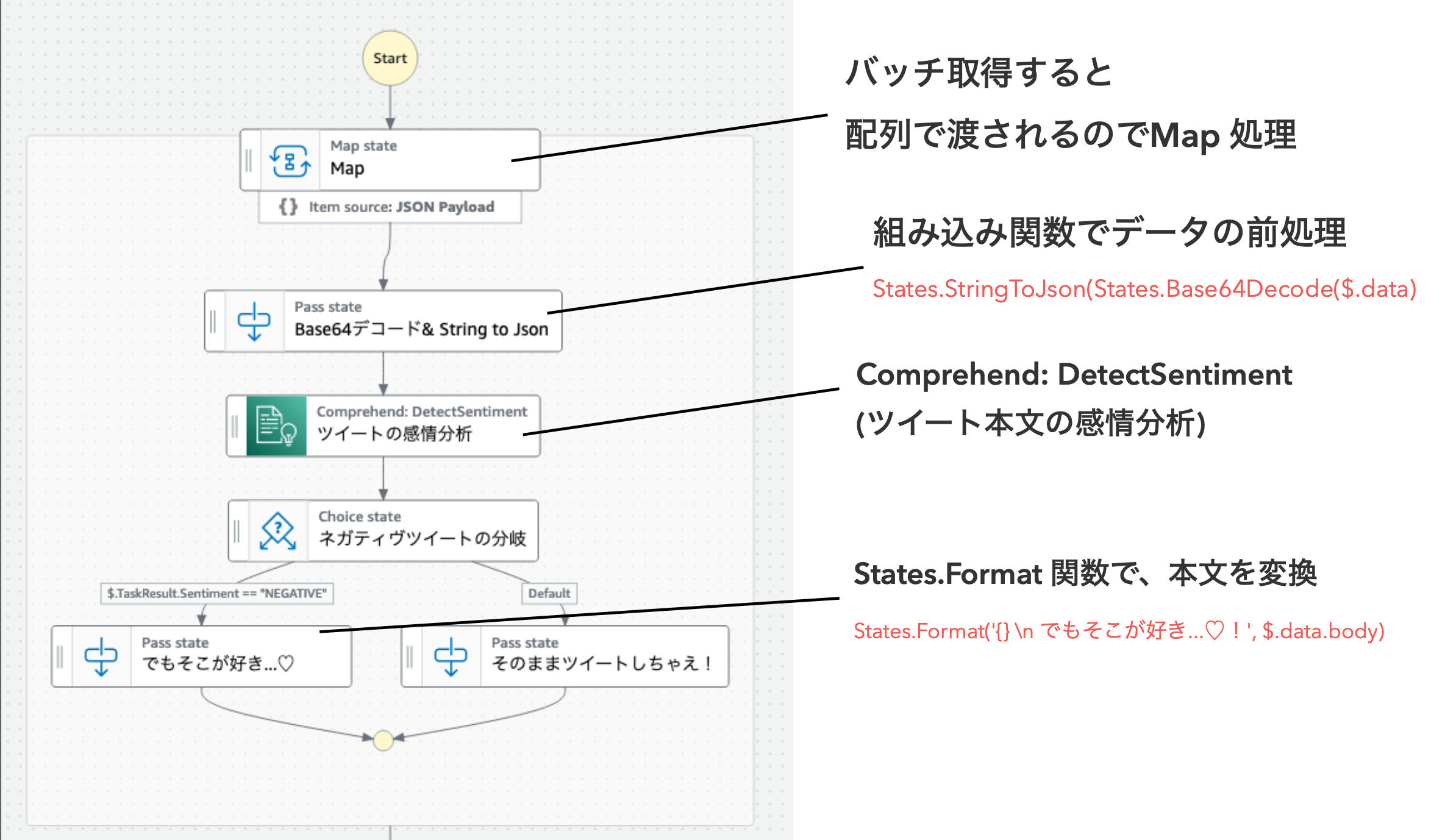
ASL コードはこちらに置いています。
後述しますがバッチ処理で複数レコードを扱っています。EventBridge Pipes の Enrich 処理の中では Lambda と Step Functions がバッチ処理をサポートしています。
イベントソースの設定でバッチサイズを設定すると、ステートマシン実行時の Input ペイロードに配列で複数レコード入ってきますので、対処できるように今回は Map を使って並列処理しています。
随所に Pass(何もしない) ステートがありますが、これは Pass の仮面をつけた Step Functions の組み込み関数による処理ステートです。Parameters フィールドで指定しています。
以下の組み込み関数を使っています。
- States.StringToJson: エスケープされた JSON 文字列をパースして JSON 形式で返却する関数です。Base64 でエンコードされた Kinesis からのデータをデコードすると
"{\"foo\": \"bar\"}"みたいな感じで文字列として返ってきます。JSONPath で扱えるよう JSON 形式に変換するために、次に説明するStates.Base64Decodeと合わせ技で利用しています。 - States.Base64Decode: Base64 でエンコードされた文字列をデコードする関数です。今回の Kinesis もそうですが、デフォルトで Base64 でのエンコード・デコードのあれこれは世の中多く存在し、Step Functions の組み込み関数で実現できるのはありがたい限りです。
- States.Format: 1つ以上の引数を扱い、文字列構築をサポートする関数です。
States.Format('{} \n でもそこが好き...♡!', $.data.body)みたいな使い方で、文字列変換用に使いました。
ツイートのポジティブ・ネガティブ判定には、Amazon Comprehend の detectSentiment を AWS SDK 統合で呼び出しています。このあたりもパラメータだけ指定して扱えるのは本当に使いやすくていいですよね。
"ツイートの感情分析": {
"Type": "Task",
"Parameters": {
"LanguageCode": "ja",
"Text.$": "$.data.body"
},
"Resource": "arn:aws:states:::aws-sdk:comprehend:detectSentiment",
"ResultSelector": {
"Sentiment.$": "$.Sentiment"
},
"ResultPath": "$.TaskResult",
"Comment": "感情分析",
"Next": "ネガティヴツイートの分岐"
}
3. バッチサイズを指定した時の挙動
EventBridge Pipes では、イベントソースからのバッチ取得及び Enrich /ターゲットへのバッチ処理をサポートしています(もちろんバッチ処理がサポートされているサービスに対してのみですが)。
注意事項としては、各サービスで読み取り/書き込みの最大バッチサイズがありますので、ターゲットとなるサービスの最大バッチサイズを超えるバッチサイズをイベントソース側に指定できません。例えば Kinesis Data Streams をイベントソースにして、バッチサイズを1000に設定して、ターゲットを SQS にすると、SQS の最大バッチサイズは 10 なので作成時にバリデーションエラーになります。
| ターゲット | 最大バッチサイズ |
|---|---|
| CloudWatch Logs | 10,000 |
| EventBridge event bus | 10 |
| Kinesis Data Firehose | 500 |
| Kinesis Data stream | 500 |
| Lambda | ペイロードサイズ上限: 6MB |
| Step Functions | ペイロードサイズ上限: 256KB |
| SNS | 10 |
| SQS | 10 |
ちなみに余談ですが Step Functions では以前まで Map 処理の並列上限が 40 だったのですが、Map の Distributed モード(10000並列まで可能)が re:invent 2022 で発表され、この辺も Pipes との合わせ技で大規模に使いやすくていいですね。
今回はイベントソースとして、Kinesis Data Streams を以下のようなパラメータでバッチ取得するようにしています。シャードレベルでの並列実行(ParallelizationFactor)などは指定していません。
- BatchSize: 3
- MaximumBatchingWindowInSeconds: 10
バッチサイズによる複数レコード取得がされると、配列内に複数レコードが含まれている感じです。(e.g. [{レコードA},{レコードB}])
ターゲットへのバッチ処理の際に、Partial batch failure(部分的なエラー処理時の残りのレコードのリトライ)もサポートされています(Enrich ではサポートされない)。
詳細は Pipes のバッチ処理に関する Docs がありますので、こちらをどうぞ。
4. その他細かいけど伝えたいこと
- Tweet 取得部分の実装について
- ここだけは流石にコードを書かざるを得なかったんですが、Tweet のリアルタイムストリーミングに関連する公式の手順やサンプルコードが公開されているので、こちらを参考に Kinesis Data Streams への PutRecord 処理だけ書きました。
- Twitter のストリーミング API を叩くための BEARER_TOKEN に関してはシークレットにあたるため、SecretManager に格納し、ECS Fargate の環境変数で
Value fromで SecretManager の ARN を指定しています。コンテナ実行時に透過的に環境変数に指定しています。細かいですがちゃんとやりました。
- Pipes の IAM 実行ロールについて
- Pipes からさまざまな AWS サービス を呼び出しますが、特にこだわりがなければ実行用の IAM ロールは Pipes で利用しているAWS サービスやリソースに応じたポリシーと一緒に自動生成できます。
困ったポイント
デバッグ系がちょっと足りていない
EventBridge Pipes では CloudWatch メトリクスと統合されており、Invocations、ExecutionFailed をはじめ TargetStageDuration や TargetStageFailed といったメトリクスのモニタリングやアラームの設定が可能です。
[2023-11-16 Update] Event Bridge Pipes にデバッグ用のロギング機能が実装されました!!!不足もなく、まさにこれを求めていました!!!
Pipes としてのロギングとしては CloudTrail のみで、ドキュメント見ても CloudTrail に各サービスの呼び出しや失敗が "invokedBy": "pipes.amazonaws.com" でロギングされるよとしか書かれていません。個人的に求めているログではなかった。
結果的に開発をしていく中で「どんなデータ流れてきている?」「え、どこで失敗してる?これ」というのを追うのがちょっと辛い感じがしました。
Step Functions の実行履歴ほどリッチなものが欲しいとは言いませんが、実行時のログとしてどのフェーズでどういう理由で Error になったのかを統合的に見れるログくらいは欲しいなと思います。
ワークアラウンドとして、Enrich フェーズで Step Functions を Pass ステート一個で通したり、ターゲット先を CloudWatch Logs に一時的に設定して、デバッグしていくような方法を取りました。
組み込みのトランスフォーム処理が配列データに最適化されていない?
EventBridge Pipes には Enrich フェーズとターゲットフェーズの前に組み込みのトランスフォーム処理を入れて、入力 Payload の簡易な変換・整形が可能です。
この機能を使って、Enrich 処理に渡す前に処理に使わない不要なカラムの削除をしようとしました。
が、1 レコードの時は問題ないのですがバッチ処理をしている時にどうしてもうまくいきませんでした。
例えばバッチ処理をして配列で流れてくる以下のようなデータに対して
[
{
"eventSource": "aws:kinesis",
"awsRegion": "us-east-1",
"details": {
"name": "インスタンスA",
"age": "RUNNING"
}
},
{
"eventSource": "aws:kinesis",
"awsRegion": "us-east-1",
"details": {
"name": "インスタンスB",
"state": "STOPPED"
}
}
]
このようなトランスフォームでは
{
"name": "<$.details.name>",
"state": "<$.details.state>"
}
2 レコード目も 1 レコード目のパラメータで上書きしてしまいます。
[
{
"name": "インスタンスA",
"state": "RUNNING"
},
{
"name": "インスタンスA",
"state": "RUNNING"
}
]
思ってた動きと違う・・・。やむを得ず、Transformer を使うのをやめてステートマシンの中で整形しました。
なんとなくバッチ処理に最適化されていないだけな気もするのですが、もっとうまいやり方があって、解決方法があるかもしれないので、もし知ってる方いれば教えて欲しいのです!
さいごに
細かいところで気になったポイントもありましたが、EventBridge Pipes を Step Functions と組み合わせて使うことで、スマートにローコードなイベントドリブンアプリケーションを構築することができました!
個人的には愛さずにはいられないサービスの一つだなと思います。来年さらなる進化に期待です!
