Hugo で人気記事ランキング機能を AWS のノーコードなサービスで作ったで
どうもやで。はまーんです。
Hugo で作った本ブログに、人気記事ランキング(閲覧数ランキング)を追加しました!この記事ページからじゃわかりませんね!ぜひトップページに行ってみてください。こんな感じになりました。
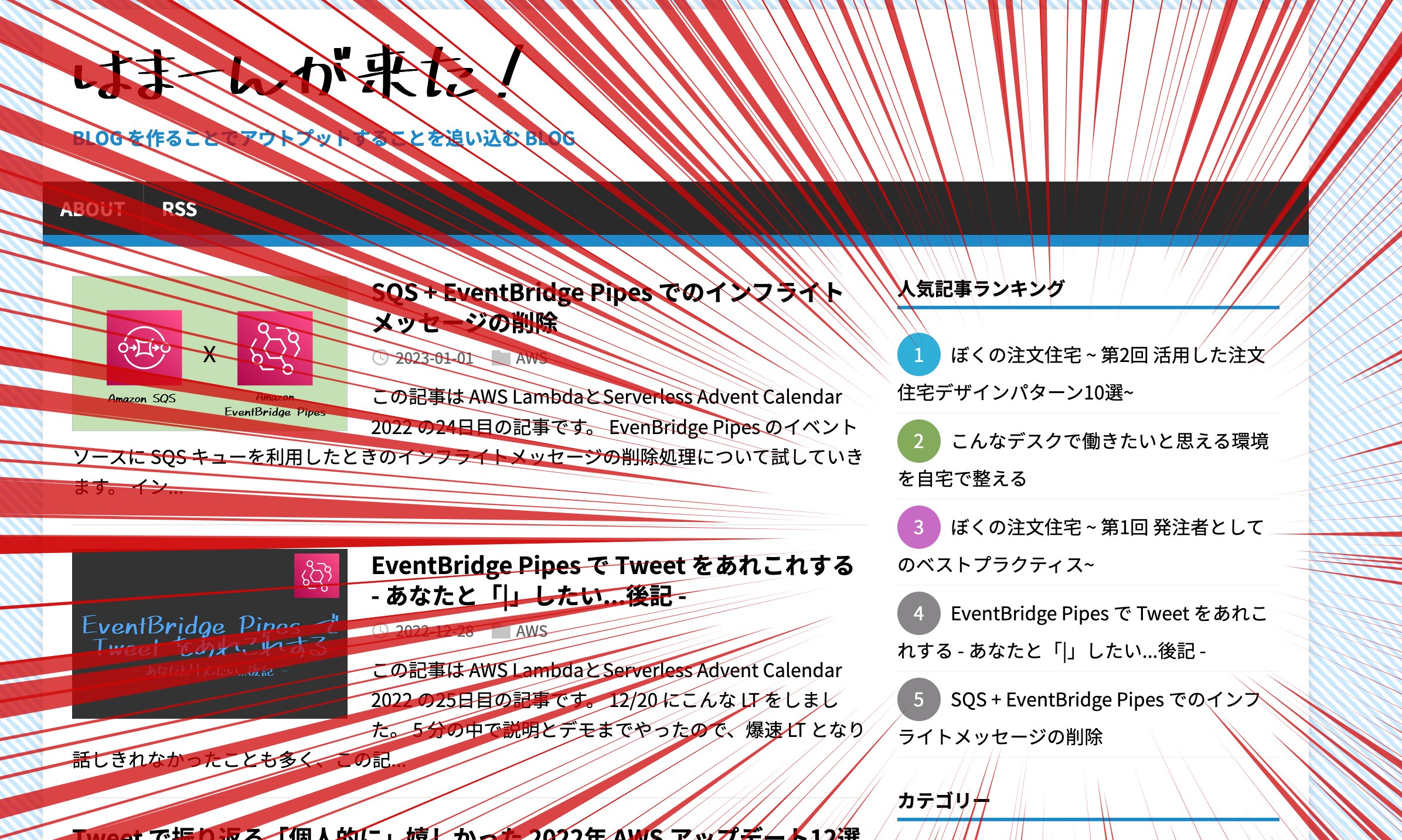
Hugo はあくまで静的サイトジェネレーターでしかないので、閲覧数を保持したりそれに応じてコンポーネントを出し分けることはできません。人気記事ランキングは Hugo は機能として持っていません。なので自分で作りました。
この記事では Hugo に追加した人気記事ランキングウィジェットについてその設計や実装について概要やこだわりを解説していきます。詳細な構築手順などは、6月に公開予定の builders.flash という AWS のブログにて公開する予定です。
開発要件
要件ですが、そもそも個人が趣味で運用している弱小ブログでしかないので、複雑なことはせずできる限りシンプルな要件にしました。
- 週間ランキング機能(そもそも Daily でランキング出すほど頻繁に記事書いていない)
- 閲覧数は GA(Google Analytics) のデータを使う
- 本ブログは Google Analytics でアクセス解析を行なっています(参考)
- 必須なデータは、閲覧数上位5件の記事の「タイトル」「URL」
- 静的サイトの良さを損ねないように、ランキングウィジェットをビルド時に生成する(APIを頻繁にたたかない)
またコード書いてゴリ押しすればなんとかなるのはわかっていましたが、今回はタイトルにある通り可能な限りノーコードであることにこだわってみました。
ランキングウィジェットの構成図
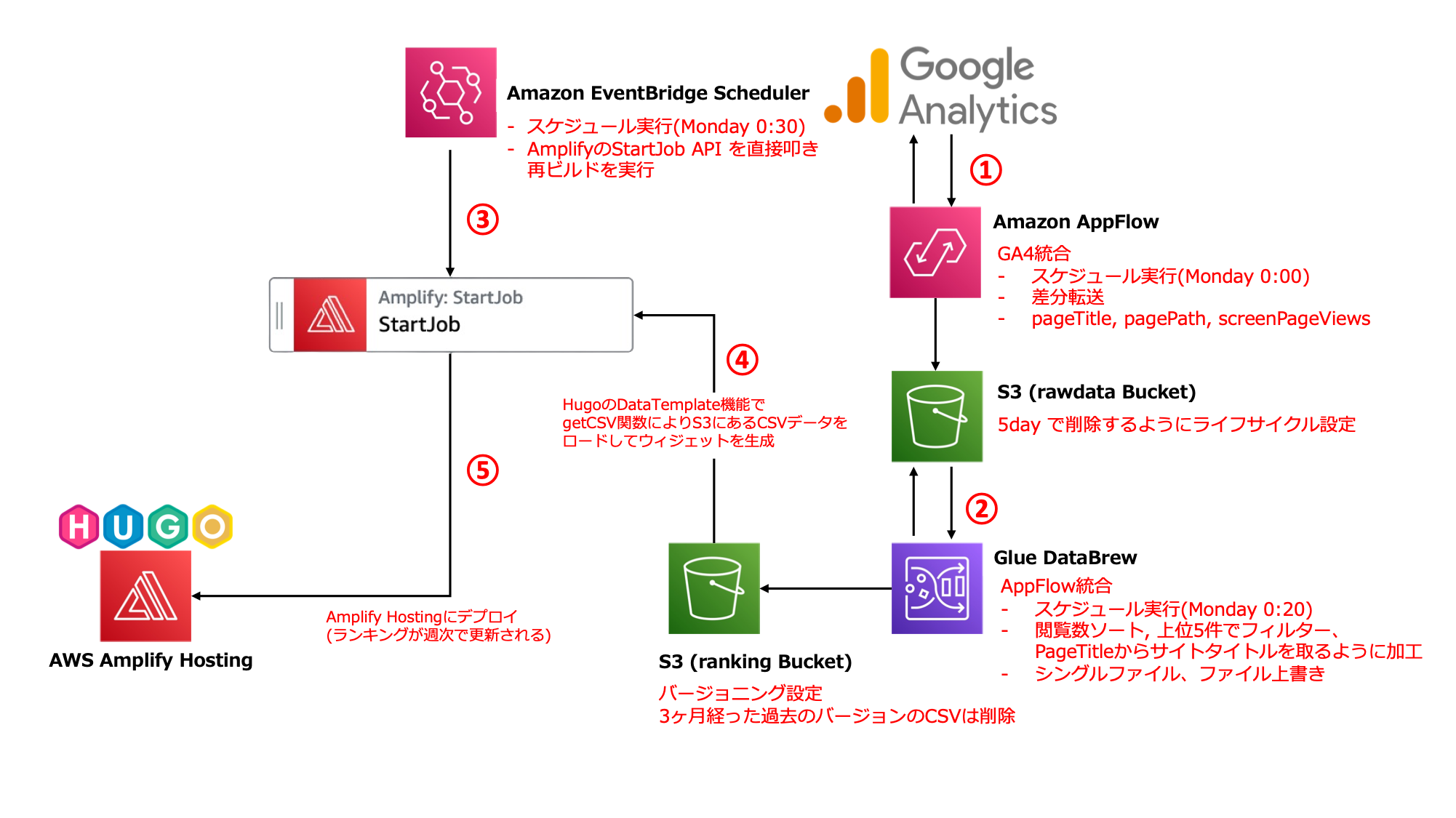
最終的な AWS アーキテクチャ図はこちらです。
前述の通り、Hugo は静的サイトジェネレータなので、GA のデータを扱うとなると「クライアントサイドで動的にレンダリングする」か「定期的にページを再生成する」かのどちらかになります。
今回は用件として週間ランキングであること・無駄な実装は減らしたい・ページの表示速度を早めることから、「定期的(週に一度)にページを再生成する」方法を取りました。
データの流れは以下の通りです。
- Amazon AppFlow の Google Analytics 4 統合機能を使い、Weekly でサイト閲覧に関するデータ(CSV)を S3 に格納する
- AWS Glue DataBrew のジョブを実行し、S3 に配置した CSV ファイルを加工して、別の S3 バケットに格納する
- Amazon EventBridge Schedulerで、Amplify の
StartJob(リポジトリの最新状態から再ビルド・再デプロイ) を実行 - Hugo のページ生成処理で、2 で S3 に配置したランキングの CSV データをもとにランキングコンポーネント生成
- Amplify Hosting にデプロイしランキングを更新する
ここからは各処理にもう少しフォーカスして解説していきます。
GA から AppFlow でデータ取得
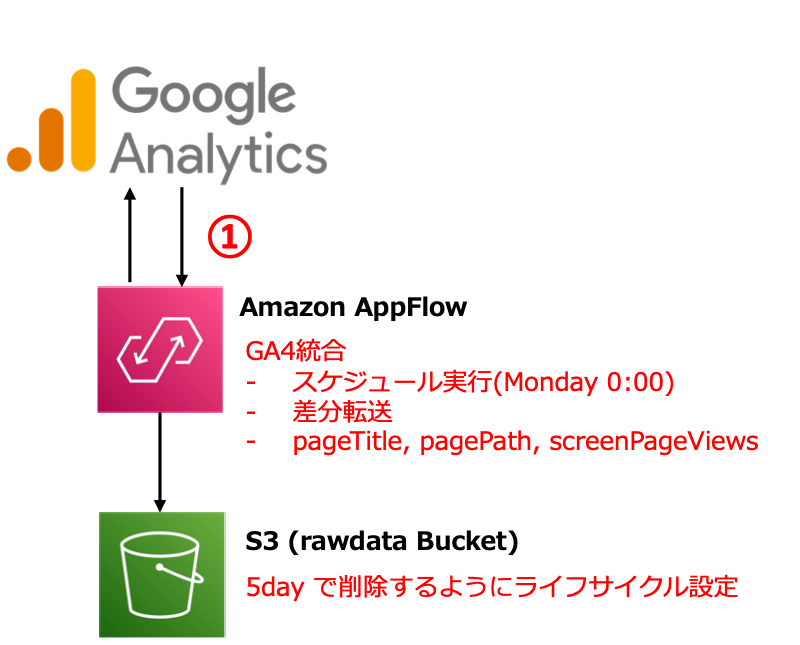
GA からのデータ取得には、Amazon AppFlow というサービスを使いました。AppFlow は SaaS アプリケーションと AWS サービス間の双方向のデータフローをノーコードで実現するサービスです。
2023 年 4 月 26 日時点で合計 76 の SaaS 製品や AWSサービスと統合できます。
2022年12月のアップデートにより Google Analytics 4(GA4) のコネクターが追加され、データソースとして GA4 が選択できるようになったとのことで、こちらのサービスを利用することにしました。
詳細な手順は別途 AWS のブログに書く予定ですが、私のブログ待てない方はこちらとそちらのブログにも既に検証記事があります。あとAWS の公式 Docs やデモ動画もご参照ください。
データソースとして GA4 を、ターゲットに Rawdata 用のS3バケットを指定しています。S3 に連携する時のデータフォーマットとしては JSON・CSV・Parquet の3種類から選べますが、今回 CSV を選んでいます。この後の章で出てくる Hugo の Data Template 機能を利用するために CSV か JSON が扱いやすく、また JSON の場合以下のようなファイル形式で連携されるためそのままだと JSON ファイルとして扱えず、変換が必要だったためです。
{
"screenPageViews": "24",
"pageTitle": "こんなデスクで働きたいと思える環境を自宅で整える - はまーんが来た!",
"pagePath": "/2020/08/my-best-wfh/"
}
{
"screenPageViews": "18",
"pageTitle": "Blue/Green デプロイと安全性と複雑性と - #AWSDevDay 2022 登壇解説 - - はまーんが来た!",
"pagePath": "/2022/11/blue-green-deploy-devday/"
}
.
.
AppFlow ではデータソースから連携するフィールドを指定し、それをターゲットにどのようにマッピングして連携するかを指定します。私はランキング機能として必要な以下の Metric や Dimension を GA4 から連携しました。ターゲットである S3 へのマッピングは特にこだわりないのでそのままです。
- Metric:screenPageViews / いわゆるPV数。ランキングの判断基準
- Dimension:pageTitle / ページのタイトル(
<title>の内容)。ランキングに表示するタイトル - Dimension:pagePath / ページのパス。リンクをつけるために利用
どんな API Dimensions & Metrics があるかは Google さんのドキュメントで確認しました。
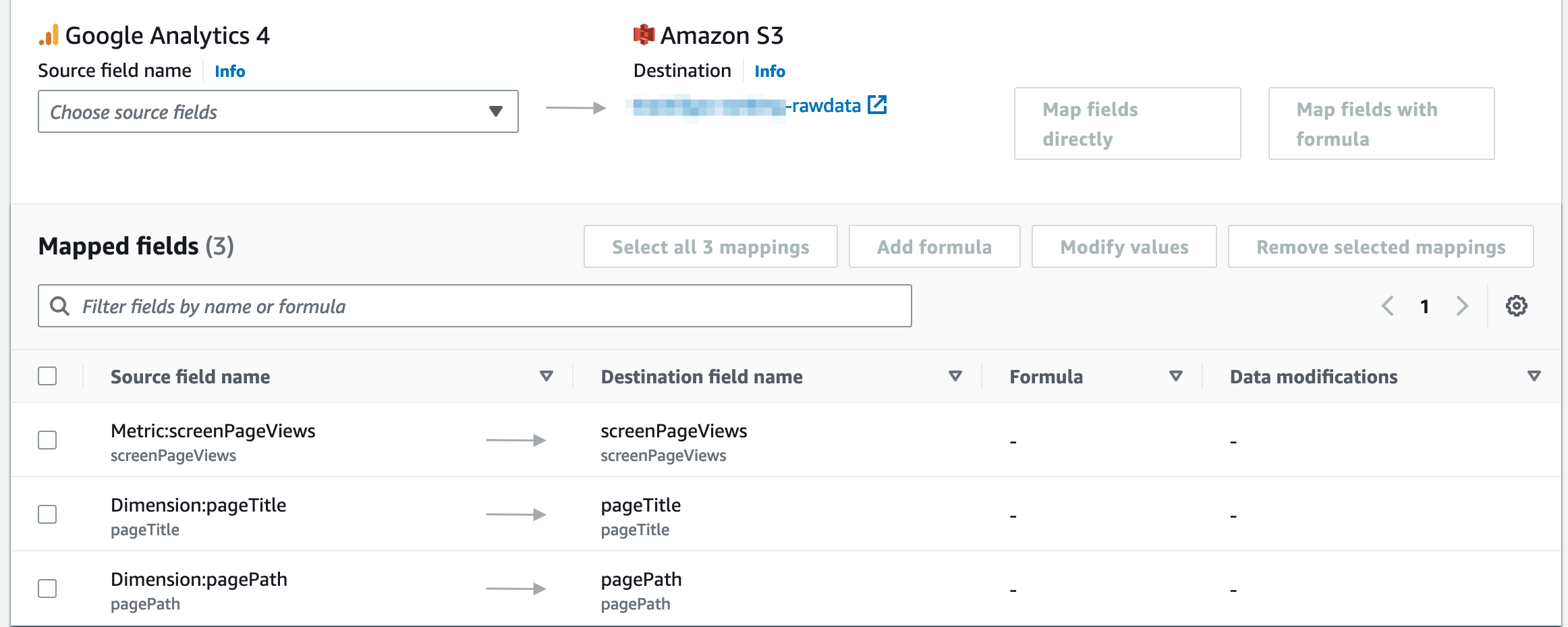
また取得するデータをフィルターできます。GAから連携されてくるデータの中には記事以外にトップページやプライバシーポリシーなど記事以外のコンテンツの閲覧データも含まれているため、記事のみが連携されるように Dimension:pagePath でフィルターしています。
さてこのフローのトリガーを設定しますが、下画像の通り、GA4 をソースとした際は、Run on demand(オンデマンド実行) か、Run flow on schedule(スケジュール実行)を選択可能です。今回は Weekly ランキング機能を作りますので、Core Report の API を Weekly で実行します。
Incremental Transfer(増分転送)モードにすることで、直近一週間分の記事閲覧情報を取得します。ちなみに増分転送モードを選択した際の最初の 1 回目は直近 30 日分のデータを取得します。もしフルデータを毎回欲しい際は Full Transfer モードを採用してください。
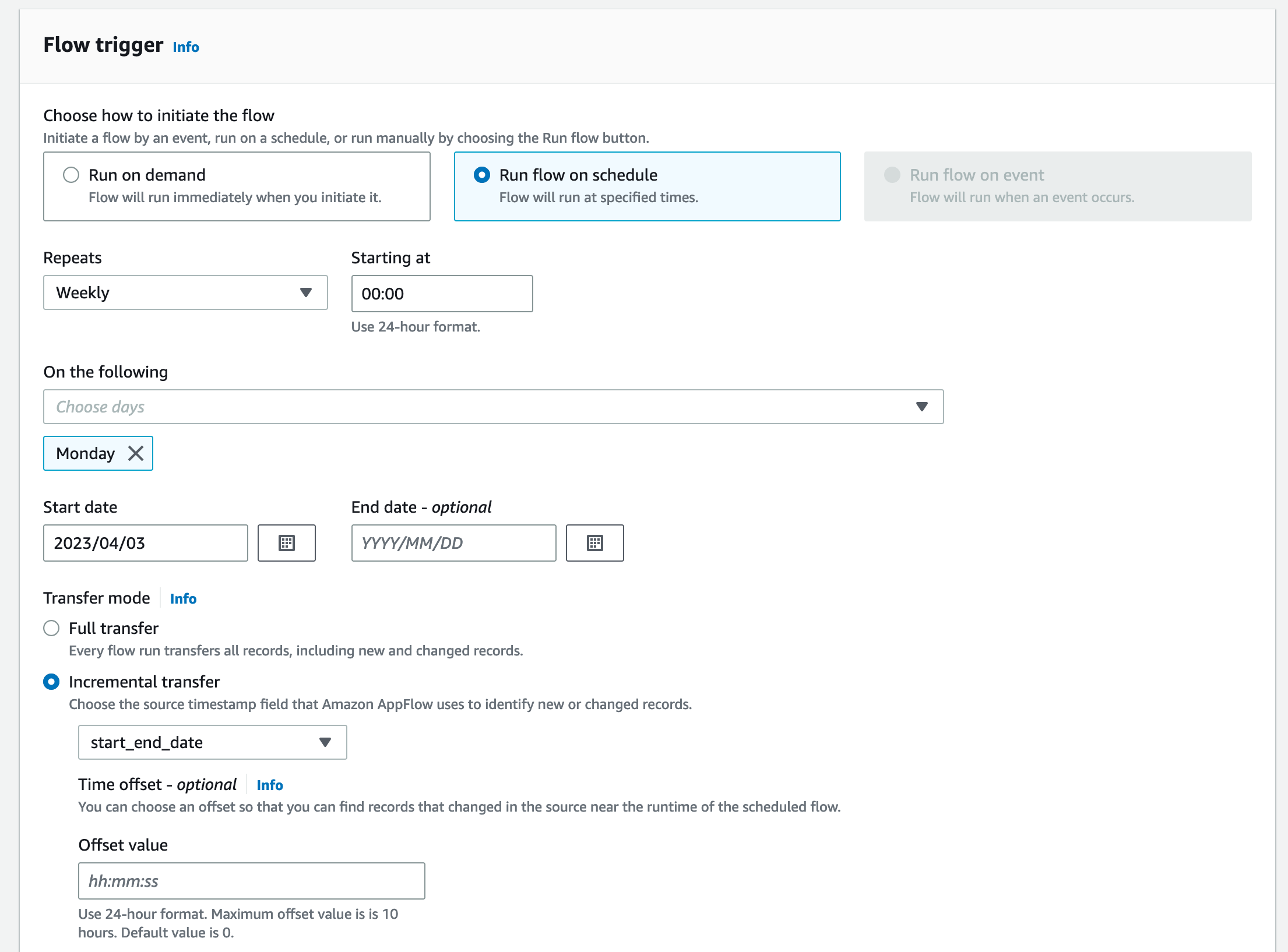
制約として、GA4 がイベントソースの際はスケジュール実行間隔は Daily より短い間隔での実行はサポートされていません。もしリアルタイム性を重視するべき要件がある場合は AWS のサンプルで GA4 のリアルタイムで取得するためのカスタムコネクターのサンプルが GitHub に公開されています。関連するブログ記事もありますので、ぜひそちらをご覧ください。
最終的に AppFlow から連携される raw data は以下のような CSV ファイルが S3 に配置されました。このファイルを Hugo でランキングウィジェットとして扱いやすい形に加工していきます。
pageTitle,pagePath,screenPageViews
"こんなデスクで働きたいと思える環境を自宅で整える - はまーんが来た!","/2020/08/my-best-wfh/","24"
"Blue/Green デプロイと安全性と複雑性と - #AWSDevDay 2022 登壇解説 - - はまーんが来た!","/2022/11/blue-green-deploy-devday/","18"
"ぼくの注文住宅 ~ 第2回 活用した注文住宅デザインパターン10選~ - はまーんが来た!","/2022/07/design-pattern-custom-home/","14"
"ぼくの注文住宅 ~ 第1回 発注者としてのベストプラクティス~ - はまーんが来た!","/2022/07/best-plactice-custom-home/","13"
"EventBridge Pipes で Tweet をあれこれする - あなたと「|」したい...後記 - - はまーんが来た!","/2022/12/pipes-with-you/","12"
"SQS + EventBridge Pipes でのインフライトメッセージの削除 - はまーんが来た!","/2023/01/pipes-with-sqs/","12"
"CDK8s が GA したので次は CDK8s+ でもっと楽したい - はまーんが来た!","/2021/12/lets-start-cdk8s/","7"
.
.
AppFlow で取得したデータを Glue DataBrew で加工する
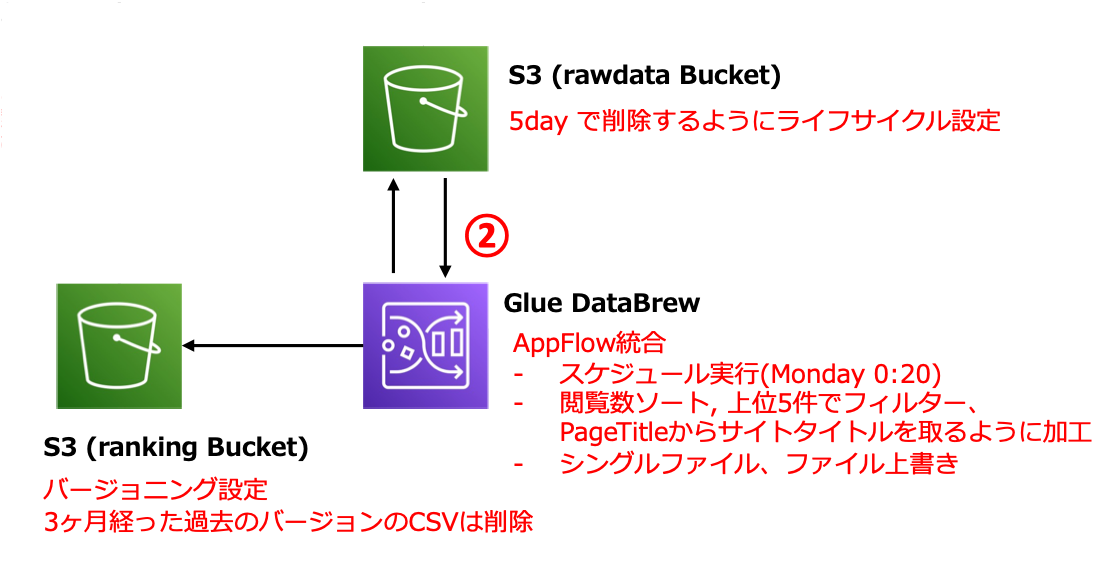
AppFlow で連携したデータをランキングコンポーネントとして Hugo からそのまま扱いやすい形に加工するために、AWS Glue DataBrew というサービスを使いました。
AWS には AWS Glue というマネージドなETLサービスがありますが、Glue DataBrew はその中でもノーコードでまた視覚的にデータの変換ジョブを作成・管理・実行するサービスです。
非エンジニアの方でも気軽に扱える個人的におすすめのサービスです。
下画像が Glue DataBrew の全体像及び利用の流れです。「データセット」が変換元になるデータの所在で、これを「プロジェクト」と呼ばれる視覚的に変換処理を定義できるワークスペースを使って「レシピ」を定義します。そして特定のデータセットに対してレシピで定義した加工をほどこす「ジョブ」を作成して実行するというのが一連の流れです。
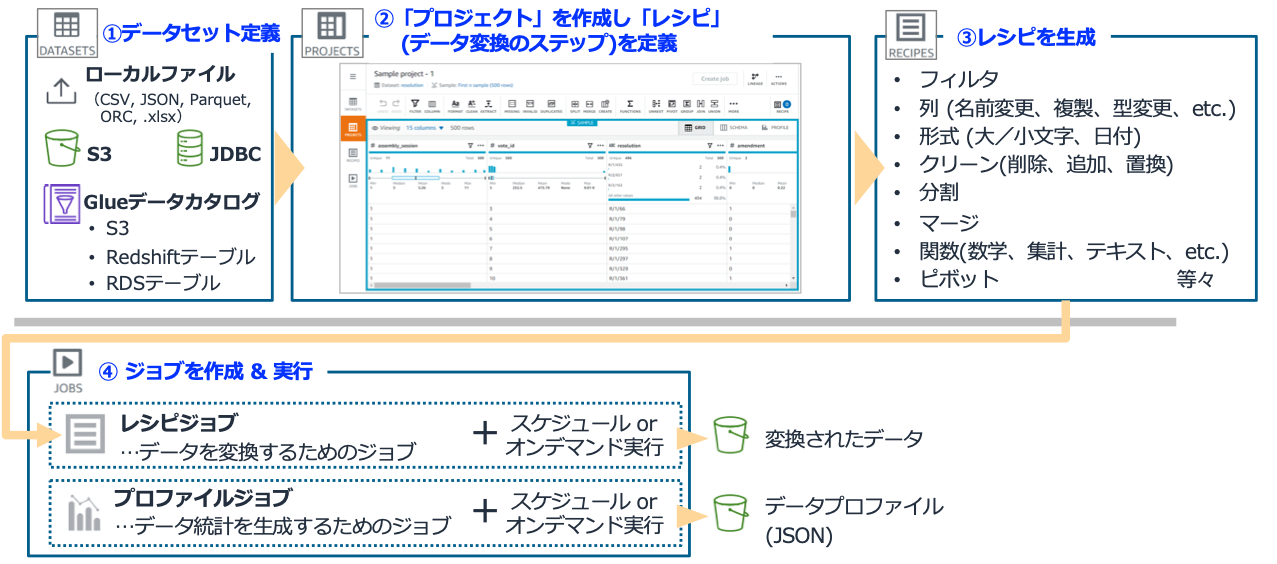
プロジェクトのUIは以下のようなイメージです。データセットを指定して操作するため実際のデータをサンプリングしながら視覚的にレシピを 「誰でも簡単に」 作っていくことができます。
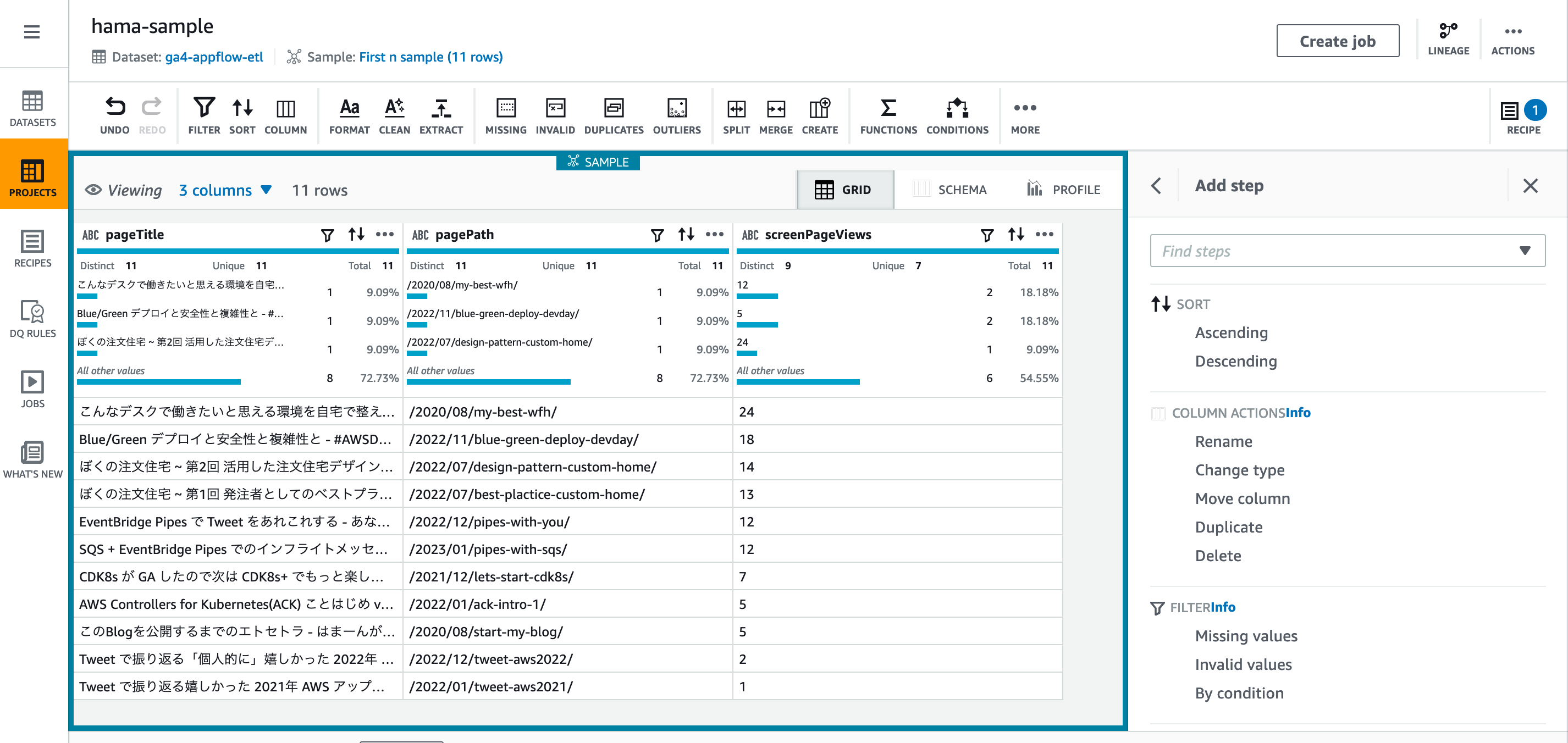
出来上がったレシピは大枠こんな感じです
- Change type of screenPageViews to Integer
- AppFlowから連携された段階では
screenPageViews(PV数)は文字列として扱われています。ソートができるように integer に変換します
- AppFlowから連携された段階では
- Sort column screenPageViews by Descending
- AppFlow からの連携の段階で既に
screenPageViewsの降順でソートされていましたが、今後もそうなる保証はないので、Glue DataBrew でもscreenPageViewsでソートします
- AppFlow からの連携の段階で既に
- Remove custom value, white spaces from pageTitle
<title>には末尾にブログ名(- はまーんが来た!)も含んでいるため、この文字列を除外処理します
- Create column ROW_NUMBER using Window functions ROW_NUMBER
- 行番号カラムを追加します
- Filter values(=< 5) by ROW_NUMBER
- 行番号カラムが 5 以下の行のみを残すようにフィルタリングします
- Hugo 側で上位 5 件だけ取ることもできますが、ダウンロードサイズを小さく保つために上位 5 件でフィルターします
「上位5件でフィルターする」というのがネイティブな機能としてなかったので、悩みましたが ROW_NUMBER 関数を使って行番号カラム作りフィルタリングするというのは個人的に上手くできたところじゃないかなと思っています!
もちろんコード書いて ETL やる方がより柔軟に色々できるのは間違いないですが、Glue DataBrew に揃ってる機能で工夫すればコード書かなくても実現できる ETL ワークロードって多いのではないかと思います。Glue DataBrew で可能な代表的な変換処理についてはこちらを御覧ください。
またレシピにはインポート機能とエクスポート機能があります。私の作ったレシピを Yaml 形式でダウンロードしたものがこちらです。
- Action:
Operation: CHANGE_DATA_TYPE
Parameters:
columnDataType: integer
sourceColumn: screenPageViews
- Action:
Operation: SORT
Parameters:
expressions: >-
[{"sourceColumn":"screenPageViews","ordering":"DESCENDING","nullsOrdering":"NULLS_BOTTOM","customOrder":[]}]
- Action:
Operation: REMOVE_COMBINED
Parameters:
collapseConsecutiveWhitespace: 'false'
customValue: '- はまーんが来た!'
removeAllPunctuation: 'false'
removeAllQuotes: 'false'
removeAllWhitespace: 'false'
removeCustomCharacters: 'false'
removeCustomValue: 'true'
removeLeadingAndTrailingPunctuation: 'false'
removeLeadingAndTrailingQuotes: 'false'
removeLeadingAndTrailingWhitespace: 'true'
removeLetters: 'false'
removeNumbers: 'false'
removeSpecialCharacters: 'false'
sourceColumn: pageTitle
- Action:
Operation: CHAR
Parameters:
endPosition: NaN
functionStepType: CHAR
ignoreCase: 'false'
startPosition: NaN
targetColumn: Char
value: '1'
- Action:
Operation: CHANGE_DATA_TYPE
Parameters:
columnDataType: integer
sourceColumn: Char
- Action:
Operation: ROW_NUMBER
Parameters:
functionStepType: ROW_NUMBER
groupByColumns: '["Char"]'
targetColumn: ROW_NUMBER
- Action:
Operation: DELETE
Parameters:
sourceColumns: '["Char"]'
- Action:
Operation: REMOVE_VALUES
Parameters:
sourceColumn: ROW_NUMBER
ConditionExpressions:
- Condition: GREATER_THAN
Value: '5'
TargetColumn: ROW_NUMBER
さて実行するジョブを定義しますが、ジョブはデータセットとレシピの組み合わせで、アウトプットフォーマットを指定する形で作成します。
そして、ジョブはデータセットである 対象 S3 バケットにある全データを扱います。やりたいことは週間ランキングを作ることなので、毎週生成するデータのみを対象とできるように、raw data 用の S3 バケットにライフサイクルルールを設定して、ファイル作成から一週間以内にデータを削除するようにしています。そもそも GA 上にもマスターデータありますので、今回は不要と考えました。もし同じことをやる上で、raw data を取っておきたい場合は S3 のオブジェクトレプリケーション機能等で退避するとかですかね。
ジョブに割り当てるノード数やタイムアウト、リトライ回数を指定し、パフォーマンスを調整することが可能です。1ノードは 4 vCPUs/16GB メモリで、ノード数はデフォルト 5で、最低でも2ノードを指定する必要があり、基本分散処理が想定されています。私がやろうとしている処理は 1 ノードで正直十分すぎるくらいで、もう少しスモールなノードサイズやノード数がサポートされてライトなユースケースでコスパ良く使えるとなおいいなと思いました。でも、コストについては後述しますがそれでもめっちゃ安く使えています。
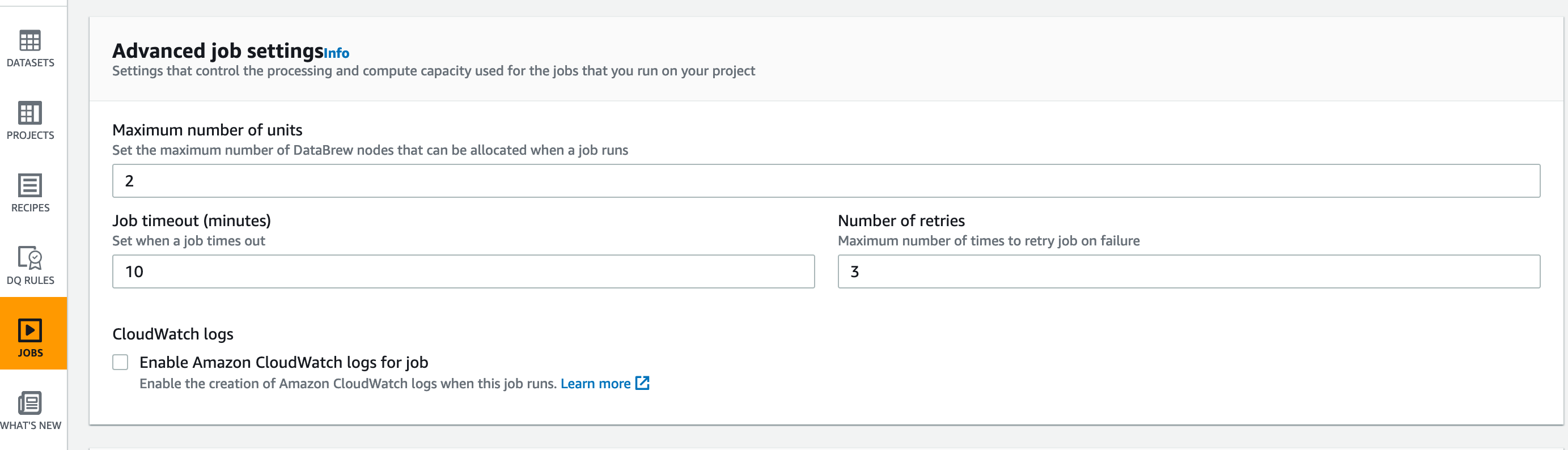
Glue DataBrew ジョブのアウトプット先としては今回利用した S3 以外にも Redshift や Snowflake なども指定可能です。ファイルタイプや圧縮方式なども複数用意されています。
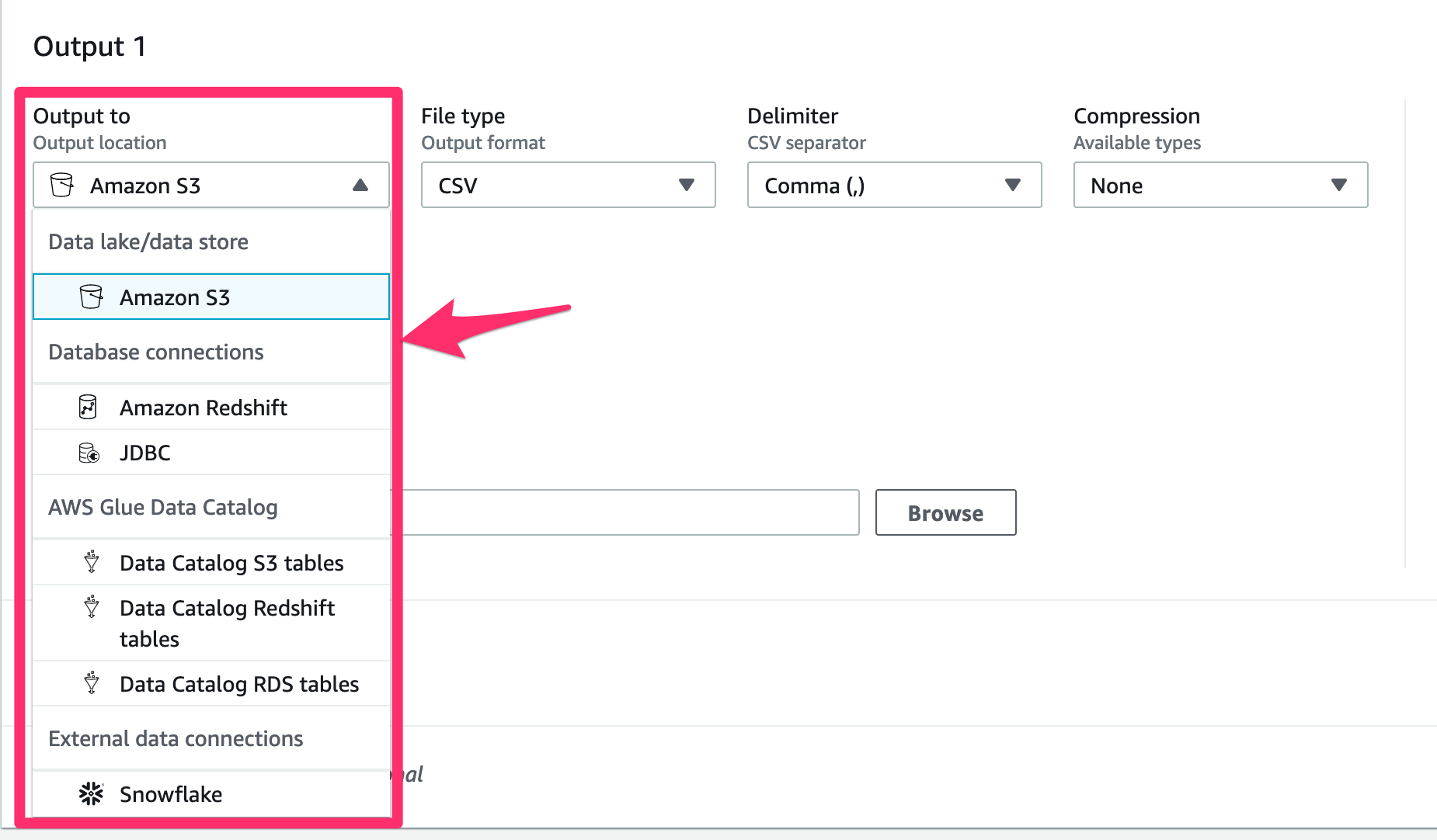
Glue DataBrew は本来データレイクの ETL として利用されることを想定しているので、S3 にアウトプットする際複数ファイルでアウトプットして、パーティショニングなどができるようになっています。
ただ今回データレイクとは全く違う目的で使っていますので、複数ファイルで吐き出されても困りますし、Timestamp 付きで別ファイルを作っていくよりは、同じファイル名で毎週更新して欲しいです。確認したところちゃんとそういう設定がありました!
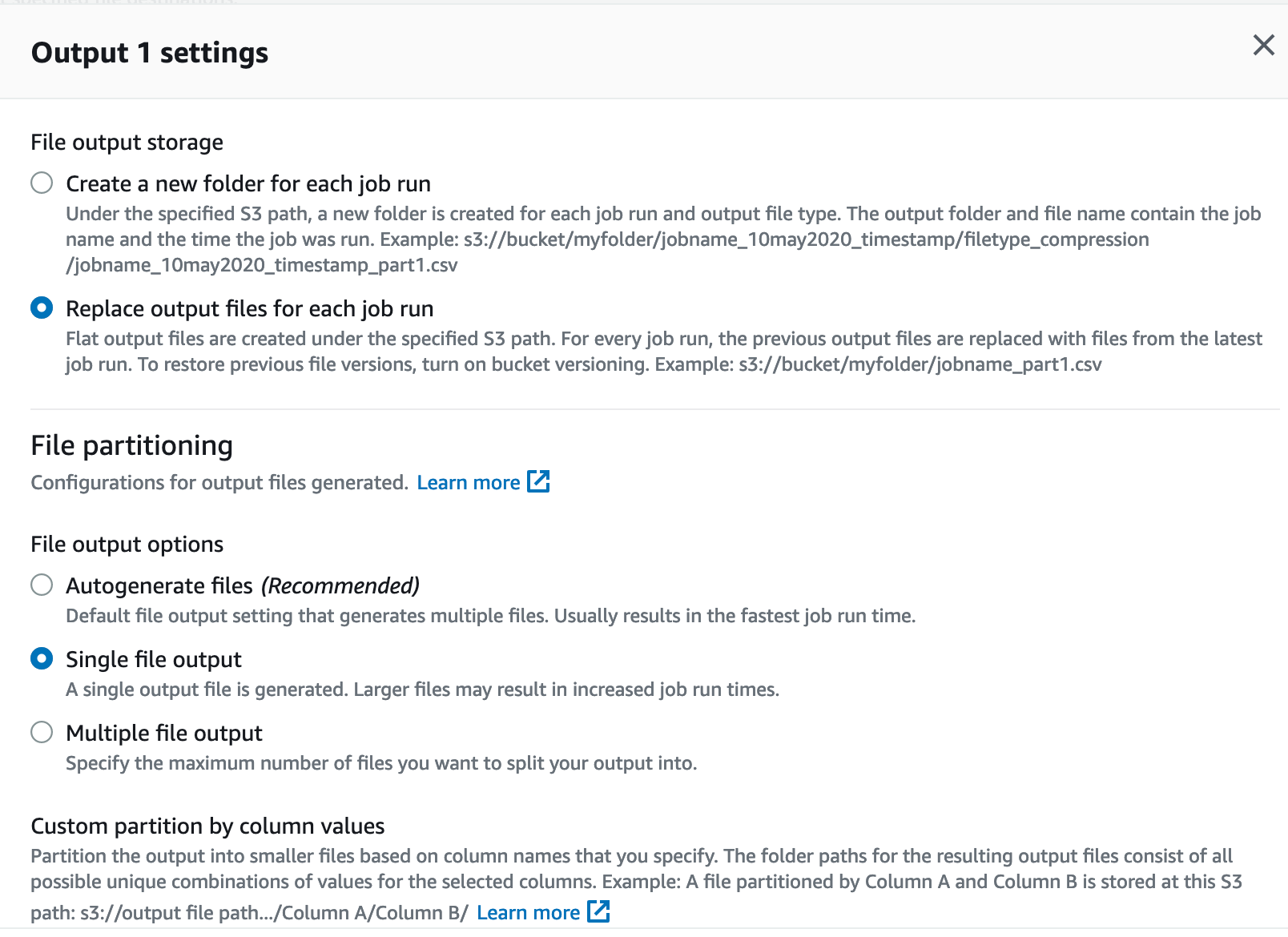
“Single file output” を指定し、“Replace output files for each job run"を指定することで、同じファイル名で週次で更新していくようなフローを実現できました。
そしてこの Glue DataBrew Job のスケジューリング実行は Glue DataBrew にもスケジューリングの機能はありますが、タイムゾーン指定など非対応だったためこの後登場する EventBridge Scheduler を使って実行しています。
最終的に Glue DataBrew から連携される加工されたデータは以下のような CSV ファイルが S3 に配置されました。シンプルでいい感じです。このデータを使ってランキングウィジェットの生成をします。
ROW_NUMBER,pageTitle,pagePath,screenPageViews
1,"こんなデスクで働きたいと思える環境を自宅で整える","/2020/08/my-best-wfh/",24
2,"Blue/Green デプロイと安全性と複雑性と - #AWSDevDay 2022 登壇解説 -","/2022/11/blue-green-deploy-devday/",18
3,"ぼくの注文住宅 ~ 第2回 活用した注文住宅デザインパターン10選~","/2022/07/design-pattern-custom-home/",14
4,"ぼくの注文住宅 ~ 第1回 発注者としてのベストプラクティス~","/2022/07/best-plactice-custom-home/",13
5,"EventBridge Pipes で Tweet をあれこれする - あなたと「|」したい...後記 -","/2022/12/pipes-with-you/",12
EventBridge Scheduler でランキングウィジェットを定期更新する
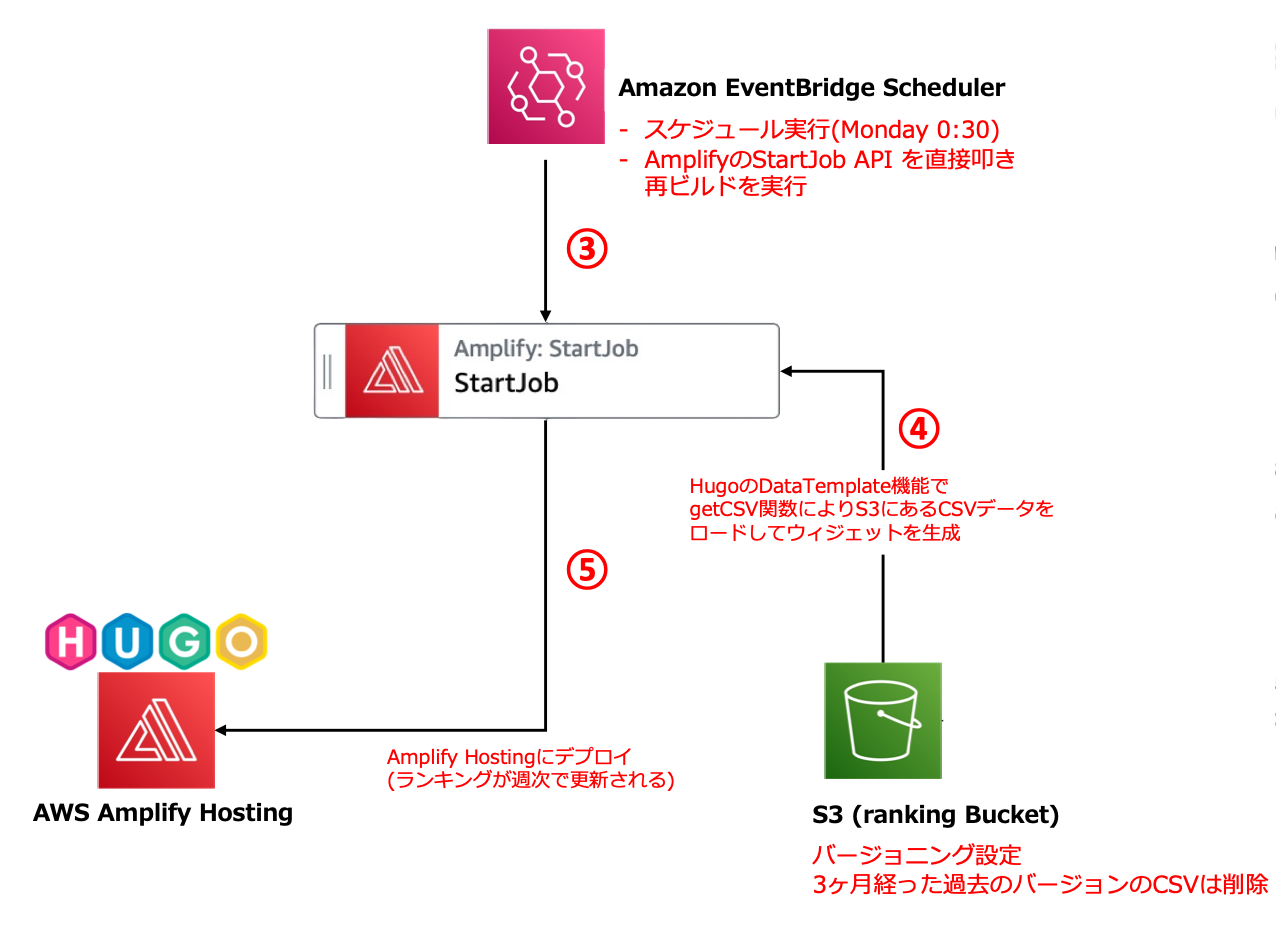
ランキングウェジェットは次の章に記載している Hugo の Data Template という機能を使っており、Hugo の静的ウェブサイトの生成処理を週に一度再実行することで、ランキングの内容を更新します。
このブログは Amplify Hosting という静的ウェブサイトホスティングの AWS サービスをつかっており、Hugo のビルド処理も Amplify の自動ビルド・デプロイ機能の中で行なっています。
この自動ビルド・デプロイを定期実行しますが、Amplifyの StartJob というAPIでこの処理を手動実行できます。
Amplifyの StartJob を定期実行する仕組みとして、Amazon EventBridge Scheduler という機能を使いました。まさにスケジューリングによるイベント発火に特化したサービスで、以下のような特徴を持っています。
- 定期実行のみならず、特定の日時刻でのワンショットなスケジュールも対応している
- タイムゾーン指定ができます
- ターゲットとして 270 をこえる AWS サービスの 6000 近い API アクションを直接実行可能です。特定の API を叩きたいだけなら、Lambda さえ不要
特に一番下が最高ですよね。個人的にStep Functions やこの EventBridge Scheduler のように、AWS の API を直接実行できるサービスめっちゃ好きです。ちょっとした処理をコーディングなしでローコードで実現可能なので、あまりコード書くのは得意じゃないなーって人でも気軽に使えます。
元々このフローでも最初は EventBridge から Step Functions を呼び出す想定をしていましたが、途中で EventBridge Scheduler から直接 Amplify の StartJob 呼べるし リトライの設定もあることに気づいて、今の設計に落ち着きました。
あとは Retry policy や dead-letter queue (DLQ) も設定可能です。 私は以下のように設定していますが、この辺は運用していく中で調整していきます。
- Maximum age of event: 3h
- Retry attempts: 10回
Hugo の Data Template 機能
Hugo には Data Template という JSON や CSV、YAML 等から動的にデータを読み込み表示する機能があります。その中でも data-driven content という機能を使いました。getJSON や getCSV といった関数が用意されており、外部またはローカルの JSON や CSV ファイルをURLで指定してビルド時に取得しウィジェットやページを生成することができます。この機能を使って、S3 上にあるCSVデータをロードして週次で動的にランキングウィジェットを生成しました。
以下のようなコードを書いています。getCSV で取得したランキングデータの入った CSV データを、1行目のヘッダーだけ除外して、range で各行をループで処理しています。ループの中で pageTitle と pagePath を抜き出してランキングウィジェットを生成しています。Javascript でフロントエンドでゴリゴリやらずに、Hugo の機能でシンプルに実現できました。
layouts/partials/ranking.html
<!-- API呼び出し -->
{{- $ranking := getCSV "," .Site.Params.widgets.rankingCsvUrl -}}
{{- $ranking_num := (.Site.Params.widgets.ranking_num | default 6) }}
{{- if $ranking }}
<div class="widget-recent widget">
<h4 class="widget__title">人気記事ランキング</h4>
<div class="widget__content">
<ul class="ranking__list">
{{- range $index, $row := (first $ranking_num $ranking) }}
{{ if gt $index 0 }}
<li class="widget__item">
<a class="widget__link" href="{{ index $row 2 }}">{{index $row 1}}</a>
</li>
{{ end }}
{{- end }}
</ul>
</div>
</div>
{{- end }}
config.toml
[Params.widgets]
rankingCsvUrl = "{{ランキングデータの S3 URL}}"
ranking_num = 6
[Params.sidebar]
widgets = ["ranking", "categories", "taglist", "twitter"]
料金
このランキング機能の概算ですが月額利用料金は15円くらいです(東京リージョン単価で計算しています)。
- AppFlow:フロー実行あたりの料金 - 0.001USD/回数、データ処理料金 - 0.09USD/GB
- 0.001USD x 4(週1実行) + 0.09USD x 0.001(月1mbくらい)= 0.004USD(約0.5円)
- DataBrew: ジョブの実行に使用された Glue DataBrew ノード時間課金 - 0.48USD/h(1分単位で課金されます)
- 0.48USD x 2(ノード) x 1/60(1回のJob実行時間が約 1min) x4(週1実行)= 0.064USD(約8円)
- 加えてDataBrew プロジェクトで視覚的にデータ加工のステップを定義していく段階で1.00USD/セッションの課金が発生します
- Amplify: ビルド & デプロイ処理にかかる料金 - 0.01 USD/min
- 0.01 USD x 1(分) x 4(週1実行)= 0.04USD(約5円)
モニタリング系
パイプライン形式の定期ジョブ実行なので、イレギュラーなエラーで失敗することも想定しておく必要があります。各所でリトライの仕組みは入れつつも、最終的にはモニタリングとしてエラー検出の仕組みを入れました。
仕組みは以下のような設計で、EventBridge Rule -> Amazon SNS -> AWS Chatbot ->Slack 通知という感じです。
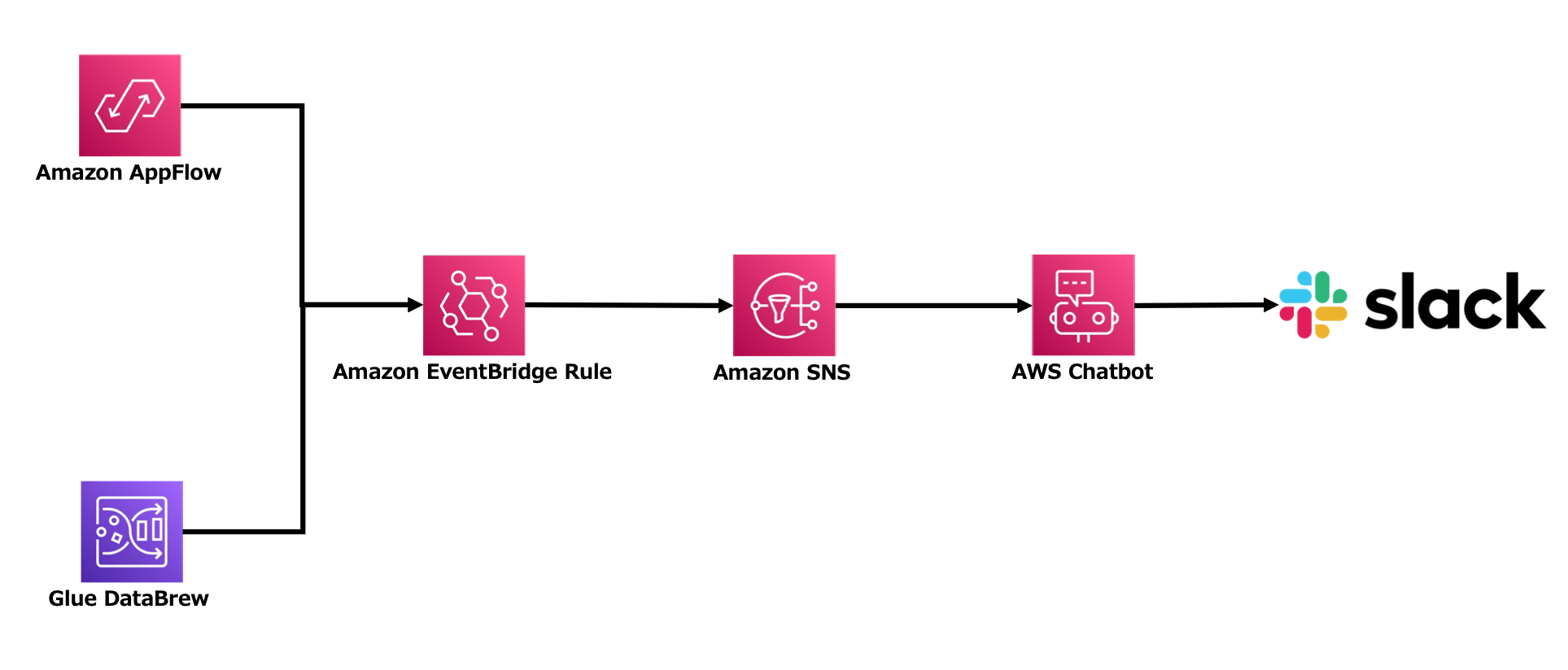
通知は AppFlow と Glue DataBrew の実行に対してとりあえず仕込みました。
- AppFlow エラー通知用 EventBridge イベントパターン
{
"source": ["aws.appflow"],
"detail-type": ["AppFlow End Flow Run Report"],
"detail": {
"status": ["Execution Failed"]
}
}
- Glue DataBrew エラー通知用 EventBridge イベントパターン
{
"source": ["aws.databrew"],
"detail-type": ["DataBrew Job State Change"],
"detail": {
"state": ["FAILED", "TIMEOUT"]
}
}
まとめ
ずっと作りたかった Hugo のランキング機能を作れて満足です!そして要件をオーバースペックにならないように整えることで、ローコスト・ノーコードな仕組みを作れて良いアーキテクティングができたな〜と個人的には満足度が高いです!
最初に書きましたが、今回登場した各サービス自体の紹介や、詳細な構築手順などは、6月に公開予定の builders.flash という AWS のブログにて公開する予定です。そちらも是非ご覧くださいませ!
